




















You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to Stash? Please start here.
Monitoring Stash
Stash has native support for monitoring via Prometheus. You can use builtin Prometheus scraper or CoreOS Prometheus Operator to monitor Stash. This tutorial will show you how this monitoring works with Stash and how to enable them.
Overview
Stash uses Prometheus PushGateway to export the metrics for backup & recovery operations. Following diagram shows the logical structure of Stash monitoring flow.
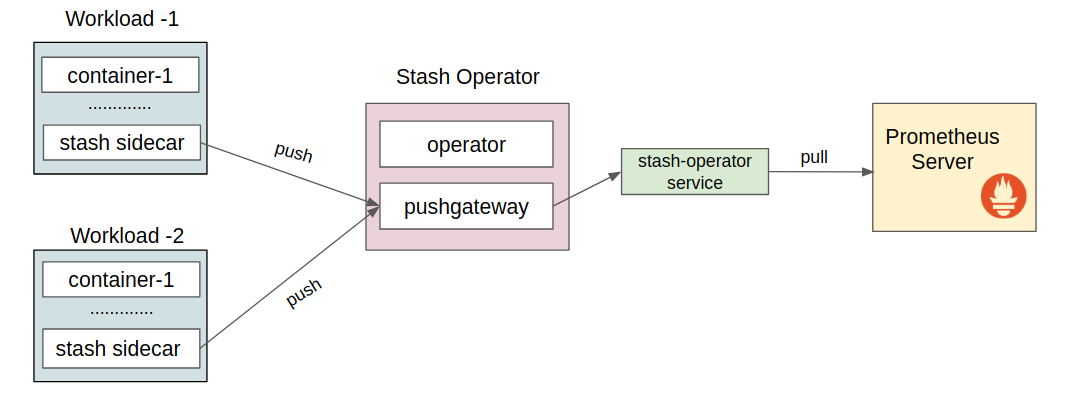
Stash operator runs two containers. The operator container runs controller and other necessary stuffs and the pushgateway container runs prom/pushgateway image. Stash sidecar from different workloads pushes their metrics to this pushgateway. Then Prometheus server scraps these metrics through stash-operator service. Stash operator itself also provides some metrics at /metrics path of :8443 port.
Backup & Recovery Metrics
Following metrics are available for stash backup and recovery operations. These metrics are accessible through pushgateway endpoint of stash-operator service.
| Metric | Uses |
|---|---|
restic_session_success | Indicates if session was successfully completed |
restic_session_fail | Indicates if session failed |
restic_session_duration_seconds_total | Seconds taken to complete restic session for all FileGroups |
restic_session_duration_seconds | Seconds taken to complete restic session for a FileGroup |
Operator Metrics
Following metrics are available for Stash operator. These metrics are accessible through api endpoint of stash-operator service.
API Server Metrics:
| Metric Name | Uses |
|---|---|
| apiserver_audit_event_total | Counter of audit events generated and sent to the audit backend. |
| apiserver_client_certificate_expiration_seconds | Distribution of the remaining lifetime on the certificate used to authenticate a request. |
| apiserver_current_inflight_requests | Maximal number of currently used inflight request limit of this apiserver per request kind in last second. |
| apiserver_request_count | Counter of apiserver requests broken out for each verb, API resource, client, and HTTP response contentType and code. |
| apiserver_request_latencies | Response latency distribution in microseconds for each verb, resource and subresource. |
| apiserver_request_latencies_summary | Response latency summary in microseconds for each verb, resource and subresource. |
| authenticated_user_requests | Counter of authenticated requests broken out by username. |
Go Metrics:
| Metric Name | Uses |
|---|---|
| go_gc_duration_seconds | A summary of the GC invocation durations. |
| go_goroutines | Number of goroutines that currently exist. |
| go_memstats_alloc_bytes | Number of bytes allocated and still in use. |
| go_memstats_alloc_bytes_total | Total number of bytes allocated, even if freed. |
| go_memstats_buck_hash_sys_bytes | Number of bytes used by the profiling bucket hash table. |
| go_memstats_frees_total | Total number of frees. |
| go_memstats_gc_sys_bytes | Number of bytes used for garbage collection system metadata. |
| go_memstats_heap_alloc_bytes | Number of heap bytes allocated and still in use. |
| go_memstats_heap_idle_bytes | Number of heap bytes waiting to be used. |
| go_memstats_heap_inuse_bytes | Number of heap bytes that are in use. |
| go_memstats_heap_objects | Number of allocated objects. |
| go_memstats_heap_released_bytes_total | Total number of heap bytes released to OS. |
| go_memstats_heap_sys_bytes | Number of heap bytes obtained from system. |
| go_memstats_last_gc_time_seconds | Number of seconds since 1970 of last garbage collection. |
| go_memstats_lookups_total | Total number of pointer lookups. |
| go_memstats_mallocs_total | Total number of mallocs. |
| go_memstats_mcache_inuse_bytes | Number of bytes in use by mcache structures. |
| go_memstats_mcache_sys_bytes | Number of bytes used for mcache structures obtained from system. |
| go_memstats_mspan_inuse_bytes | Number of bytes in use by mspan structures. |
| go_memstats_mspan_sys_bytes | Number of bytes used for mspan structures obtained from system. |
| go_memstats_next_gc_bytes | Number of heap bytes when next garbage collection will take place. |
| go_memstats_other_sys_bytes | Number of bytes used for other system allocations. |
| go_memstats_stack_inuse_bytes | Number of bytes in use by the stack allocator. |
| go_memstats_stack_sys_bytes | Number of bytes obtained from system for stack allocator. |
| go_memstats_sys_bytes | Number of bytes obtained by system. Sum of all system allocations. |
HTTP Metrics:
| Metrics | Uses |
|---|---|
| http_request_duration_microseconds | The HTTP request latencies in microseconds. |
| http_request_size_bytes | The HTTP request sizes in bytes. |
| http_requests_total | Total number of HTTP requests made. |
| http_response_size_bytes | The HTTP response sizes in bytes. |
Process Metrics:
| Metric Name | Uses |
|---|---|
| process_cpu_seconds_total | Total user and system CPU time spent in seconds. |
| process_max_fds | Maximum number of open file descriptors. |
| process_open_fds | Number of open file descriptors. |
| process_resident_memory_bytes | Resident memory size in bytes. |
| process_start_time_seconds | Start time of the process since unix epoch in seconds. |
| process_virtual_memory_bytes | Virtual memory size in bytes. |
How to Enable Monitoring
You can enable monitoring through some flags while installing or upgrading or updating Stash. You can also chose which monitoring agent to use for monitoring. Stash will configure respective resources accordingly. Here, are the list of available flags and their uses,
| Script Flag | Helm Values | Acceptable Values | Default | Uses |
|---|---|---|---|---|
--monitoring-agent | monitoring.agent | prometheus.io/builtin or prometheus.io/coreos-operator | none | Specify which monitoring agent to use for monitoring Stash. |
--monitoring-backup | monitoring.backup | true or false | false | Specify whether to monitor Stash backup and recovery. |
--monitoring-operator | monitoring.operator | true or false | false | Specify whether to monitor Stash operator. |
--prometheus-namespace | monitoring.prometheus.namespace | any namespace | same namespace as Stash operator | Specify the namespace where Prometheus server is running or will be deployed |
--servicemonitor-label | monitoring.serviceMonitor.labels | any label | For Helm installation, app: <generated app name> and release: <release name>. For script installation, app: stash | Specify the labels for ServiceMonitor. Prometheus crd will select ServiceMonitor using these labels. Only usable when monitoring agent is prometheus.io/coreos-operator. |
You have to provides these flags while installing or upgrading or updating Stash. Here, are examples for both script and Helm installation process are given which enable monitoring with prometheus.io/coreos-operator Prometheuse server for backup & recovery and operator metrics.
Helm 3:
$ helm install stash-operator appscode/stash-community --version v2021.04.12 \
--namespace kube-system \
--set monitoring.agent=prometheus.io/coreos-operator \
--set monitoring.backup=true \
--set monitoring.operator=true \
--set monitoring.prometheus.namespace=monitoring \
--set monitoring.serviceMonitor.labels.k8s-app=prometheus
Helm 2:
$ helm install appscode/stash-community --name stash-operator --version v2021.04.12 \
--namespace kube-system \
--set monitoring.agent=prometheus.io/coreos-operator \
--set monitoring.backup=true \
--set monitoring.operator=true \
--set monitoring.prometheus.namespace=monitoring \
--set monitoring.serviceMonitor.labels.k8s-app=prometheus
YAML (with Helm 3):
$ helm template stash-operator appscode/stash-community --version v2021.04.12 \
--namespace kube-system \
--no-hooks \
--set monitoring.agent=prometheus.io/coreos-operator \
--set monitoring.backup=true \
--set monitoring.operator=true \
--set monitoring.prometheus.namespace=monitoring \
--set monitoring.serviceMonitor.labels.k8s-app=prometheus | kubectl apply -f -